
- 데이터 모델을 만들면 장고에서 자동으로 ORM을 제공해준다.
- Managers는 모델 인스턴스가 아닌 클래스에서만 접근 가능함
- INSERT문 : 특정 model 객체 생성 후 save 또는 model.objects.create(column 별 값 지정)
difference between objects.create() and object.save() in django orm
u = UserDetails.objects.create(first_name='jake',last_name='sullivan') u.save() UserDetails.objects.create() and u.save() both perform the same save() function. What is the difference? Is there any
stackoverflow.com
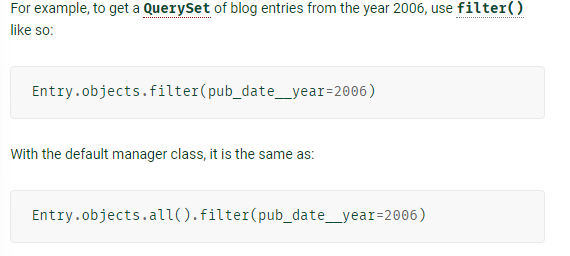
- SELECT문 : QuerySet 자체가 SELECT와 동일 ex) Model.objects.all()은 모든 Blog 객체를 담은 쿼리셋 반환
- WHERE or LIMIT 구문 : filter(), exclude(), get() 활용 -> filter/exclude의 경우 체이닝해서 써도 되고 바로 써도 됨
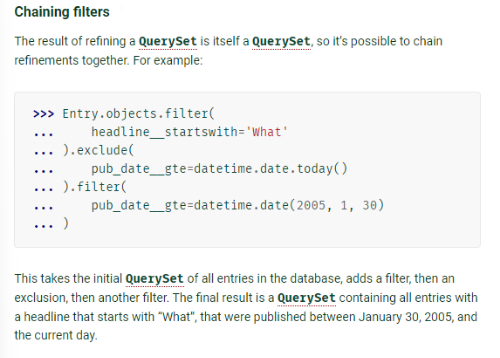
- QuerySet을 가공할 때마다 새로운 쿼리셋을 얻기 대문에 각각 다른 객체로 취급된다.
- QuerySet은 처리 요청이 있기 전까지는 지연처리됨 -> 이러한 특성 때문에 가독성 있는 코드를 짤 수 있음(줄줄이 체이닝을 하는 것과 별개로 쿼리셋을 작성하는 것은 같은 효과)
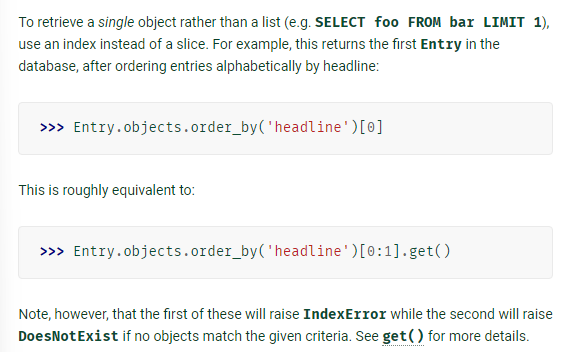
- get()은 쿼리 결과로 특정 객체를 반환할 것을 알고 있을 때 쓰면 직접 객체로 받아올 수 있어서 좋고, filter는 QuerySet형태로 받아오기 때문에 filter한 후 0번째 인덱스로 슬라이싱해서 쓸건지 말건지는 상황에 따라 다르게 활용해야 함
- get()의 조건에 해당하는 데이터가 없으면 DoesNotExist 예외 발생, 여러 개의 데이터가 있으면 MultipleObjectsReturned 에러 발생
- limiting QuerySet : 일반적인 슬라이싱을 사용하면 query를 다시 날리는 게 아니라 기존에 all()로 받아온 queryset을 재가공하는 것 뿐이지만 step을 활용한 슬라이싱은 query를 다시 날리게 됨
- 또한 python에서 제공하는 -1 인덱싱을 queryset에 사용할 수 없음

- 단일 객체(데이터)를 조회하기 위해서는 슬라이싱 보다는 인덱싱을 활용하자
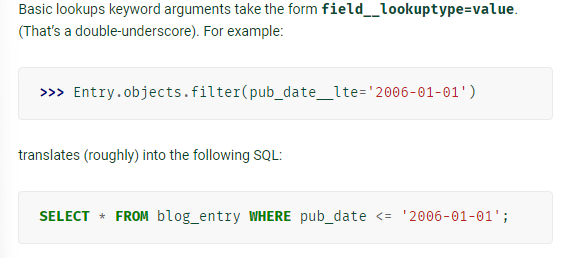
- filed__lookuptype=value 형식으로 where 문 선언 (자세한건 https://docs.python.org/3/tutorial/controlflow.html#tut-keywordargs 참고)
- 일반적으로는 model field 명을 filter 조건에 넣어야 하지만 외래키인 경우는 예외적으로 _id를 붙여서 filter가능
-> 잘못된 filed명 넣었을 때 TypeError 발생
- field__exact=value : where field = value
- iexact : 대소문자 구분 없음(case-insensitive)
- contains : LIKE '%~%'
- startswith, endswith, istartwith, iendswith
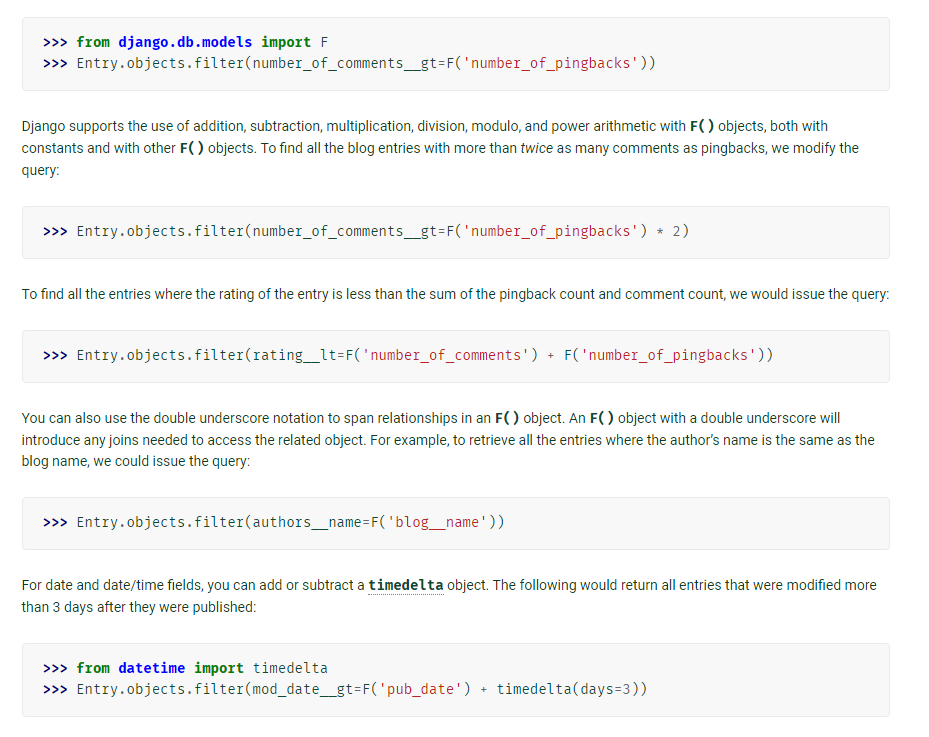
- F expressions으 경우 모델 객체 안의 서로 다른 필드 값을 비교할 때 사용한다.
-> 비트연산도 지원하긴 하지만 많이 쓸지는 의문이다.
-> 날짜 필드로 연산 시에는 timedelta 객체 활용할 수 있다.
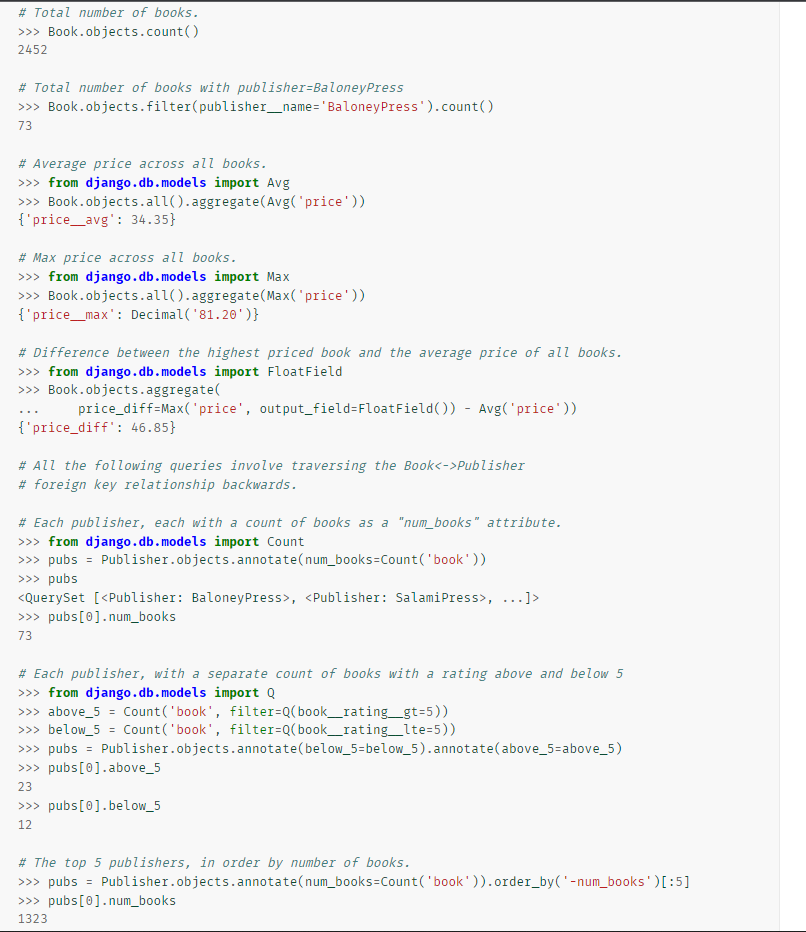
- aggregate, count, Q, annotate Cheat Sheet
-> 집계할 때 aliasing 사용 가능 aggregate(aliasing Name = Count ~Max, Min 등등)
-> 컬럼을 새로 DB에 만들기보다 일시적으로 필요할 때 annotate 활용하면 좋아 보임
- pk가 id일 경우 pk = id, 즉 특정 field가 primarykey라면 해당 fieldname 대신 pk라고 작성가능

- %(percent sign 또는 wildcard)와 _(underscore) 문법 사용 시 파이썬에서 fieldname__contains='%' 또는 '_'를 필터링하는 구문은 SELECT ... WHERE fieldname LIKE '%\%%' 또는 '%\_%';과 같다
댓글