
시스템 성능을 공부하다 보면 이런 단어들이 계속 등장한다.
- 워드 크기(word size)
- 레지스터(register)
- 프로세스(process)
- 스레드(thread)
- runnable
- OS 스레드
- goroutine
문제는 이 단어들이 너무 “추상적”이라는 점이다.
정확히 무엇을 의미하는지 모르면, 성능 분석은 전부 감으로 하게 된다.
이번 글에서는
CPU 관점에서 실제로 무슨 일이 일어나는지 기준으로
핵심 개념을 정리한다.
1. 워드 크기(Word Size), 레지스터(Register), 정수 크기(Integer Size)
이 세 개는 자주 섞인다.
하지만 서로 다른 층위의 개념이다.
1.1 워드 크기(Word Size)
CPU가 한 번에 “자연스럽게” 처리하는 기본 데이터 크기
- 32비트 CPU → 워드 크기 32비트 (4바이트)
- 64비트 CPU → 워드 크기 64비트 (8바이트)
64비트 시스템에서:
- 포인터 크기 = 8바이트
- size_t = 8바이트
즉,
워드 크기는 CPU의 기본 체급이다.
CPU는 이 크기의 데이터 연산을 가장 효율적으로 처리한다.
1.2 레지스터(Register) 크기
CPU 내부에 있는 초고속 저장 공간의 비트 수
예를 들어 x86-64 아키텍처를 보자.
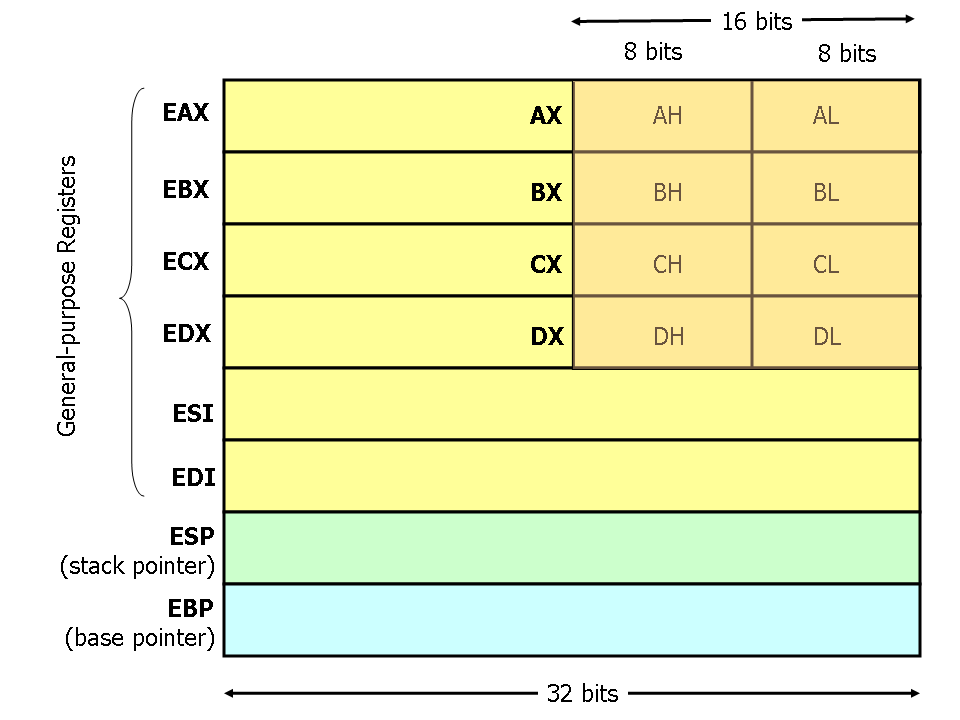

- RAX = 64비트
- EAX = 하위 32비트
- AX = 16비트
- AL = 8비트
하나의 물리 레지스터를 여러 크기로 접근할 수 있다.
보통:
레지스터 크기 ≈ 워드 크기
하지만 SIMD 레지스터는 다르다.
- AVX → 256비트
- AVX-512 → 512비트
즉, 모든 레지스터가 워드 크기와 같지는 않다.
1.3 정수 크기(Integer Size)
프로그래밍 언어가 정의한 타입의 크기
64비트 리눅스 기준(C 언어):
타입크기
| char | 1바이트 |
| short | 2바이트 |
| int | 4바이트 |
| long | 8바이트 |
| long long | 8바이트 |
중요한 점:
int는 64비트 시스템에서도 4바이트다.
정수 크기는 언어의 약속이지
CPU 워드 크기와 반드시 일치하지 않는다.
1.4 세 개의 관계 요약
개념의미
| 워드 크기 | CPU 기본 연산 단위 |
| 레지스터 크기 | CPU 내부 저장공간 크기 |
| 정수 크기 | 언어 타입 크기 |
한 줄 정리:
워드는 CPU의 체급
레지스터는 CPU의 손
정수 크기는 언어의 약속
2. 프로세스(Process), 스레드(Thread), Task
이제 실행 단위를 보자.
2.1 프로세스(Process)
독립된 메모리 공간을 가진 실행 단위
특징:
- 고유 주소 공간
- 파일 디스크립터
- PID
프로세스는 서로 메모리를 직접 공유하지 않는다.
2.2 스레드(Thread)
CPU에서 실제로 실행되는 흐름
하나의 프로세스 안에는 여러 스레드가 존재할 수 있다.
- 코드 공유
- 힙 공유
- 전역 변수 공유
- 각자 스택은 별도
중요한 점:
CPU는 프로세스를 실행하지 않는다.
CPU는 스레드를 실행한다.
2.3 리눅스에서의 Task
리눅스 커널은 내부적으로
프로세스와 스레드를 구분하지 않는다.
둘 다 task_struct로 관리된다.
즉,
커널이 스케줄링하는 최소 단위 = task
3. running vs runnable
성능 분석에서 이 차이는 매우 중요하다.
running
지금 이 순간 CPU 위에서 실행 중
물리적으로 코어를 점유하고 있다.
runnable
실행 가능하지만 CPU를 기다리는 상태
run queue에 올라가 있으며
CPU가 비면 즉시 실행된다.
왜 중요한가?
예:
- 8코어 시스템
- runnable 8개 → 정상
- runnable 30개 → CPU 경쟁 발생
이때 나타나는 현상:
- context switch 증가
- 캐시 붕괴
- IPC 감소
- latency 증가
즉,
문제는 “많다”가 아니라
“줄 서 있다”이다.
4. OS 스레드 vs 유저 스레드
이제 스케줄링 층위를 보자.
4.1 OS 스레드 (Kernel Thread)
- 커널이 직접 관리
- run queue에 올라감
- 컨텍스트 스위치 비용 큼
- 기본 스택 ~1MB
스레드 전환 시:
- 레지스터 저장/복원
- 커널 모드 개입
- 캐시/TLB 영향
4.2 유저 스레드 (User-Level Thread)
예:
- goroutine (Go)
- 일부 coroutine
특징:
- 커널은 모름
- 런타임이 관리
- 커널 전환 없음
- 전환 비용 낮음
- 스택 작음 (수 KB)
핵심 차이
누가 스케줄링을 하느냐
- OS 스레드 → 커널
- 유저 스레드 → 런타임
5. Go의 goroutine은 왜 수만 개여도 괜찮은가?
Go는 M:N 스케줄링을 사용한다.
- G (goroutine)
- M (OS thread)
- P (processor token)
구조는:
수만 개 G
↓
소수 M (보통 코어 수 수준)
↓
CPU
즉,
수만 개의 goroutine이 있어도
실제 OS 스레드는 코어 수 근처다.
단, 주의
CPU-bound 작업이면?
- 코어 수 이상 실행 불가
- 나머지는 runnable 상태
goroutine이 많다고
CPU 한계를 넘을 수는 없다.
핵심 정리
- 워드 크기는 CPU의 기본 연산 단위
- 레지스터는 CPU 내부 초고속 저장 공간
- 정수 크기는 언어의 정의
- 리눅스의 스케줄링 단위는 task
- runnable이 코어 수보다 많으면 성능 저하
- goroutine은 OS 스레드를 “묶어서” 사용하는 경량 스레드
마치며
시스템 성능을 이해하려면
추상적인 단어가 아니라
CPU에서 실제로 무슨 일이 일어나는가
를 기준으로 생각해야 한다.
다음 글에서는
동시성에서 가장 헷갈리는 개념인
- 원자성(Atomicity)
- 격리성(Isolation)
- 무결성(Integrity)
- 가시성(Visibility)
- 일관성(Consistency)
을 하나의 예시로 완전히 분해해본다.
'프로그래밍공부(Programming Study)' 카테고리의 다른 글
| 원자성, 격리성, 일관성 — 동시성 개념을 물리적으로 이해하기 (0) | 2026.02.20 |
|---|---|
| Potpourri (자잘하지만 중요한 주제들) (2) | 2025.09.10 |
| Security and Cryptography (3) | 2025.09.09 |
| 메타프로그래밍(Metaprogramming)과 DevOps: 빌드·의존성·CI 제대로 이해하기 (0) | 2025.09.08 |
| 커맨드라인 환경 정리 – 효율적인 셸 활용법 (2) | 2025.08.30 |
댓글