

이 글은 브렌던 그렉(Brendan Gregg)의
시스템 성능 엔지니어링(Systems Performance, Second Edition)을 읽으며
핵심 내용을 정리하고, 이해를 돕기 위해 일부 설명을 덧붙인 글입니다.
들어가며
시스템 성능 엔지니어링(Systems Performance Engineering)은 단순히
“느린 시스템을 빠르게 만드는 기술”이 아니다.
그보다 더 근본적으로는, 시스템이 어떻게 동작하는지를 이해하고,
문제가 발생했을 때 어디를, 어떤 관점(perspective)에서 바라봐야 하는지에 대한 학문이다.
‘1장 소개(Introduction)’에서는
- 시스템 성능(System Performance)이 무엇인지
- 누가 성능을 책임지는지
- 그리고 어떤 관점과 도구(tool)로 성능 문제에 접근해야 하는지를
전체적인 그림에서 개괄적으로 다룬다.
이 장에서 설명하는 개념들은 이후 모든 장에서 반복적으로 등장하며,
시스템 성능 엔지니어링을 이해하기 위한 출발점(starting point)이자 기준점(reference point)이 된다.
1.1 시스템 성능(System Performance)
시스템 성능 분석이란 무엇인가
시스템 성능 분석(System Performance Analysis)은
컴퓨터 시스템 전체의 성능을 연구하는 과정이다.
여기서 ‘전체’란 단순히 애플리케이션 코드만을 의미하지 않는다.
- 데이터가 지나가는 전체 경로(data path)
- 저장 장치(storage)
- 네트워크(network)
- 커널(kernel)
- 시스템 라이브러리(system libraries)
- 애플리케이션(application)
- 분산 시스템(distributed system)이라면
- 여러 서버(servers)
- 여러 애플리케이션
- 서비스 간 호출 관계(service-to-service communication)
이 모든 요소가 성능에 영향을 줄 수 있으며, 따라서 모두 분석 대상이 된다.
Action Item
대상 환경의 데이터 경로(data path)를 보여주는 다이어그램이 없다면, 반드시 찾아보거나 직접 그려보자.
성능 분석의 출발점은 “데이터가 어디로 흘러가는지”를 아는 것이다.
시스템 성능 분석의 일반적인 목표
시스템 성능 분석의 궁극적인 목표는 다음 두 가지로 요약된다.
- 지연시간(latency)을 줄여 사용자 경험(user experience)을 개선
- 컴퓨팅 비용(computing cost) 절감
비효율(inefficiency)을 제거하고, 처리량(throughput)을 높이며,
시스템 전반을 튜닝(tuning)함으로써 같은 비용으로 더 많은 일을 처리할 수 있게 된다.
풀 스택(full stack) 관점
성능 분석에서 말하는 풀 스택(full stack)이란 다음을 모두 포함한다.
- 애플리케이션(application)
- 런타임(runtime)
- 시스템 라이브러리(system libraries)
- 커널(kernel)
- 하드웨어(hardware, 흔히 metal이라 부름)
상황에 따라 풀 스택의 범위는 다르게 사용되기도 한다.
예를 들어, 어떤 팀에서는 데이터베이스–웹 서버–애플리케이션까지만을 풀 스택이라 부르기도 한다.
중요한 점은 컴파일러(compiler)조차도 성능에 영향을 줄 수 있기 때문에,
성능 엔지니어링의 관점에서는 이 또한 스택의 일부로 본다는 것이다.
1.2 역할(Role)
시스템 성능은 특정 직군 하나의 책임이 아니다.
- 시스템 관리자(system administrator)
- 애플리케이션 개발자(application developer)
- 네트워크 엔지니어(network engineer)
- 데이터베이스 관리자(database administrator)
- 웹 관리자(web administrator)
- 각종 운영 및 지원 인력(operations & support)
각자는 자신의 전문 영역(domain)에 집중하기 때문에,
성능 문제의 근본 원인(root cause)을 찾기 위해서는
팀 간 협업(cross-team collaboration)이 필수적이다.
이때 성능 엔지니어는 다음과 같은 역할을 수행한다.
- 여러 팀을 연결하여 환경 전반을 아우르는 분석
- 복잡한 성능 문제의 근본 원인 규명
- 성능 분석 및 수용량 계획(capacity planning)을 위한 도구 발굴 및 개발
저자 브렌던 그렉(Brendan Gregg)은
Netflix에서 클라우드 성능 팀의 일원으로 일하며,
마이크로서비스와 SRE 팀을 지원하고 모두가 사용할 수 있는 성능 도구를 만들어왔다.
규모가 큰 조직에서는 성능 엔지니어링 팀 역시 세분화되어,
- 커널 전문가
- 특정 언어/런타임 전문가
- 성능 분석 도구 전문가
와 같이 깊이 있는 지원이 가능해진다.
1.3 활동(Activity)
전통적인 제품 개발 프로세스에서의 성능 활동
- 성능 목표 및 성능 모델 수립
- 프로토타입의 성능 특성 파악
- 테스트 환경에서 성능 분석
- 회귀 테스트(non-regression testing)
- 출시 전 벤치마크 수행
대상 환경에서 문제 발생 시
- 개념 증명(PoC) 테스트
- 프로덕션 성능 튜닝
- 프로덕션 모니터링
- 성능 문제 발생 시 분석 수행
사후 단계
- 장애 사후 분석(incident review)
- 성능 분석 도구 개선 및 개발
성능 엔지니어링은
개발 전–개발 중–운영 중–사후 분석까지
시스템 생애주기(system lifecycle) 전반에 걸쳐 반복된다.
1.4 관점(Perspective)
성능 분석에는 크게 두 가지 관점이 있다.
워크로드 관점(Workload View)
워크로드(workload)
→ 애플리케이션(application)
→ 시스템 라이브러리/시스템 콜(system call)
→ 커널(kernel)
→ 장치(device)
리소스 관점(Resource View)
장치(device)
→ 커널(kernel)
→ 시스템 콜/라이브러리
→ 애플리케이션
→ 워크로드
같은 문제라도 어디서부터 바라보느냐에 따라 전혀 다른 인사이트를 얻을 수 있다.
관측가능성 도구 vs 실험 도구
1.7 관측가능성(Observability)
관측가능성(observability)이란 관찰을 통해 시스템을 이해하는 능력이다.
- 카운터
- 프로파일링
- 트레이싱
을 포함하며, 벤치마크 도구는 제외된다.
벤치마크는 시스템 상태를 변화시키기 때문이다.
일반적으로는
→ 관측가능성 도구를 먼저,
→ 테스트 환경이 유휴 상태라면 실험 도구를 활용하는 것이 바람직하다.
1.8 실험(Experiment)
실험 도구의 대표적인 예는 벤치마킹 도구(benchmark tools)다.
- 인공적인 워크로드를 생성
- 시스템에 부하를 주고 성능 측정
단, 실험 자체가 성능을 교란할 수 있으므로 주의가 필요하다.
- 매크로 벤치마크: 실제 사용자 요청 시뮬레이션
- 마이크로 벤치마크: CPU, 디스크, 네트워크 등 개별 구성 요소 테스트
마이크로 벤치마크는 보통 결과가 안정적이고 디버깅이 쉽다.
“여러분에게는 관측과 실험이라는 두 손이 있습니다.
한 가지만 사용하는 것은 한 손으로 문제를 해결하려는 것과 같습니다.”
성능 관측가능성의 기초 개념
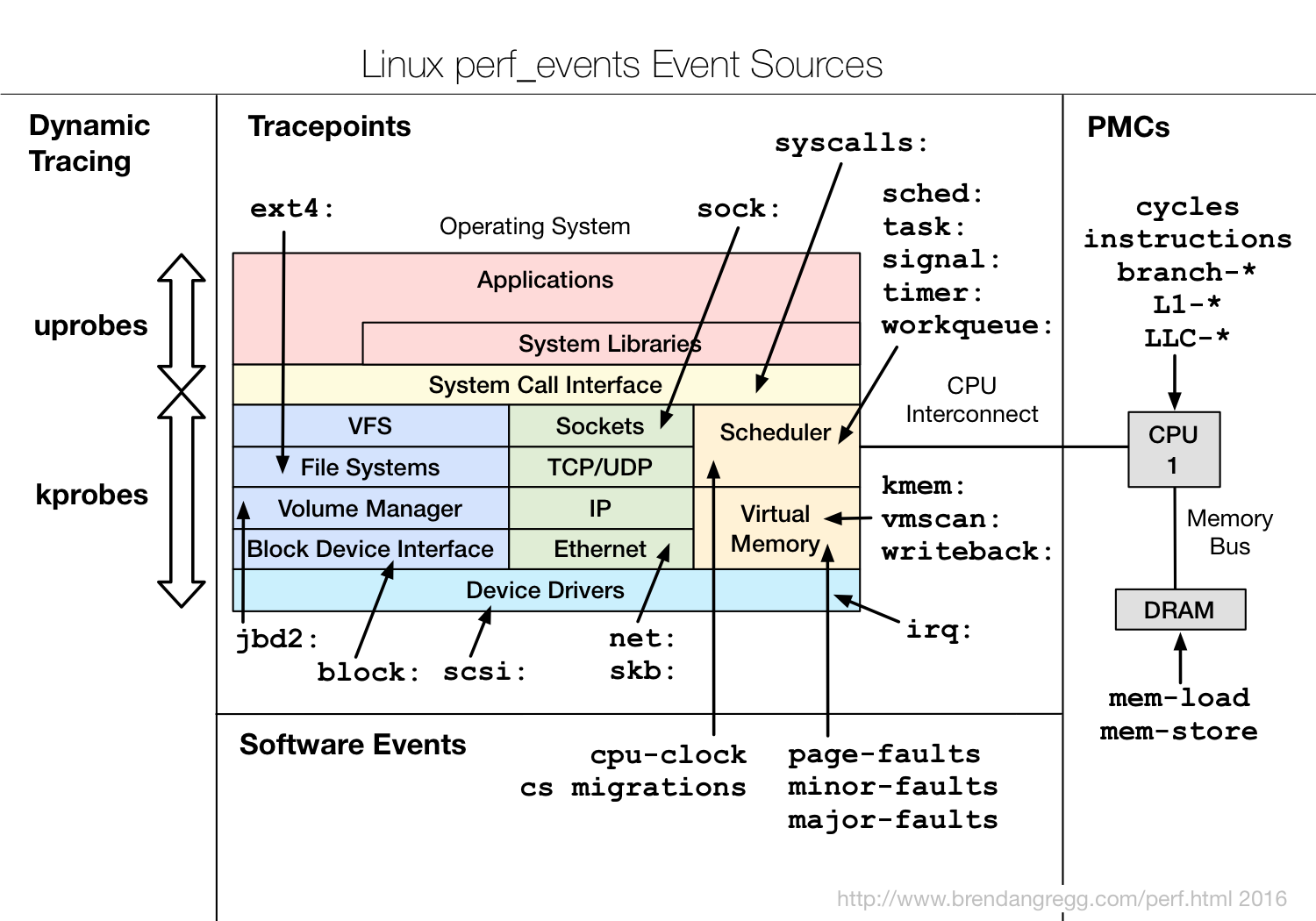

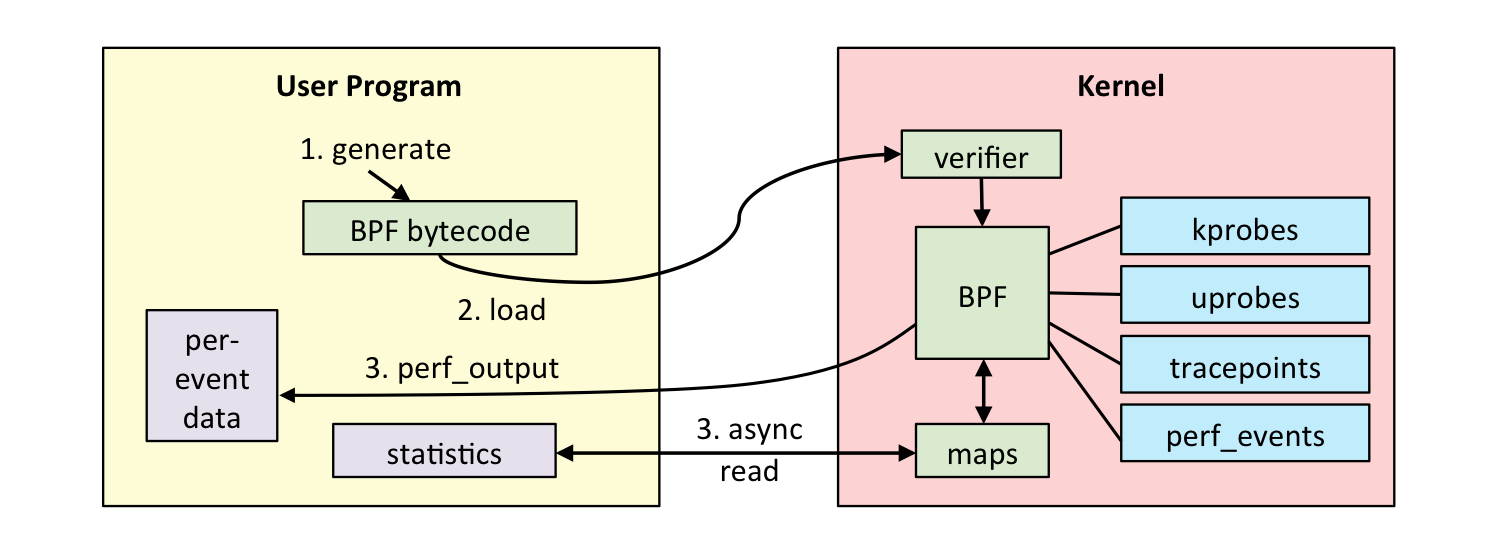
카운터와 지표
- 카운터: 시스템의 상태와 활동을 수치로 표현
- 지표: 그중 모니터링 대상으로 선별된 통계
예: vmstat는 /proc 기반 커널 카운터를 요약해 보여준다.
프로파일링 & 플레임 그래프
- 프로파일링: 샘플링 기반으로 시스템의 전반적인 상태 파악
- 플레임 그래프: CPU 사용 패턴을 시각적으로 표현
CPU 문제뿐 아니라 비정상적인 사용 패턴을 식별하는 데 매우 유용하다.
트레이싱
- 시스템 내부 이벤트를 기록하고 추적
- 실시간 처리 또는 사후 분석에 활용
정적 계측과 동적 계측
- 정적 계측: 코드에 미리 정의된 계측점
- 커널: tracepoint
- 사용자 공간: USDT
- 동적 계측: 실행 중 계측점 삽입
- 실행 흐름을 방해하지 않고 통계 수집 가능
BPF(eBPF)
- 커널 내에서 안전하고 빠르게 실행되는 범용 환경
- BCC, bpftrace 등 다양한 도구의 기반 기술
- 현대 리눅스 성능 분석의 핵심
1.10 방법론과 60초 리눅스 체크리스트
방법론의 필요성
방법론이 없으면 성능 분석은 무작위 시도가 된다.
USE Method, 워크로드 특성화, 지연시간 분석 등은 체계적인 접근을 돕는다.
60초 리눅스 성능 체크리스트
| 구분 | 명령어 | 확인 항목 | 해석 포인트 |
|---|---|---|---|
| 시스템 부하 | uptime |
Load Average (1/5/15분) | 부하가 증가 추세인지, 일시적 스파이크인지 판단 |
| 커널 상태 | dmesg -T | tail |
커널 로그 | OOM 이벤트, 드라이버 오류, 하드웨어 에러 |
| 전체 상태 | vmstat -SM 1 |
실행 큐, 스와핑, CPU 사용률 | 시스템 전반의 병목 여부 파악 |
| CPU 분산 | mpstat -P ALL 1 |
CPU 코어별 사용률 | 특정 CPU 집중 시 스레드 분산 문제 의심 |
| 프로세스 | pidstat 1 |
프로세스별 CPU 사용률 | 비정상적 고 CPU 프로세스 탐지 |
| 디스크 I/O | iostat -sxz 1 |
IOPS, 스루풋, 대기 시간 | 디스크 병목 여부 및 %util 확인 |
| 메모리 | free -m |
메모리 사용량 | 캐시 포함 실제 여유 메모리 확인 |
| 네트워크 | sar -n DEV 1 |
인터페이스 I/O | 네트워크 트래픽 이상 여부 |
| TCP | sar -n TCP,ETCP 1 |
연결 수, 재전송 | 네트워크 오류 및 혼잡 징후 |
| 종합 | top |
CPU/메모리/프로세스 | 전체 상태를 한눈에 재확인 |
활용 팁
- 이 표는 “원인 분석”이 아니라 “이상 징후 탐색”용
- 이상이 보이는 지점을 기준으로
→ 프로파일링, 트레이싱, BPF 도구로 정밀 분석 진행
마무리
1장은 이후 모든 장의 기초 체력을 다지는 장이다.
성능 분석은 도구 이전에 관점과 사고방식의 문제임을 강조하며,
“어디를 보고, 무엇을 먼저 볼 것인가”에 대한 기준을 제시한다.
다음 장부터는 이 개념들이 구체적인 방법론과 도구로 확장된다.
'독서(Reading) > 시스템 성능 엔지니어링' 카테고리의 다른 글
| 시스템 성능 엔지니어링: 네트워크 기초 개념 정리 (1) | 2026.06.03 |
|---|
댓글